Prometheus+Grafana 实现告警功能
Prometheus 编写告警规则
Prometheus 要实现告警,需要跟 Alertmanager 配合使用
Prometheus 服务中的警告规则发送警告到 Alertmanager。
然后 Alertmanager 管理这些警告。包括 silencing, inhibition,aggregation,以及通过一些方法发送通知
例如:email,PagerDuty 和 HipChat。
在 30 上操作
# 创建 prometheus 告警规则配置文件
mkdir -p /data/prometheus/rules && vim /data/prometheus/rules/node.yml
# 组告警
groups:
# 组名,报警规则组名称
- name: general.rules
# 定义角色
rules:
# 告警名称。
- alert: 磁盘使用率
# 表达式,获取磁盘使用率 大于 80% 触发
expr: 100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
# 持续时间,表示持续 1 分钟获取不到信息,则触发报警。0 表示不使用持续时间
for: 1m
# 定义当前告警规则级别
labels:
# 指定告警级别。
severity: warning
# 注释,告警通知
annotations:
# 调用标签具体指附加通知信息
# 自定义摘要
summary: "Instance {{ $labels.instance }} :{{ $labels.mountpoint }} 分区使用率过高"
# 自定义具体描述
description: "{{ $labels.instance }} : {{ $labels.job }} :{{ $labels.mountpoint }} 这个分区使用大于百分之80% (当前值:{{ $value }})"
# 把配置文件复制到容器
docker cp /data/prometheus/rules cf_prometheus:/etc/prometheus/
# 修改 prometheus 主配置文件 prometheus.yml
vim /data/prometheus/prometheus.yml
global:
# 默认抓取数据的时间间隔
scrape_interval: 15s
# 触发告警检测的时间
evaluation_interval: 60s
# 告警规则配置文件
rule_files:
- /etc/prometheus/rules/node.yml
# 重启 prometheus
docker restart cf_prometheus
在网页端可以看到设置的规则
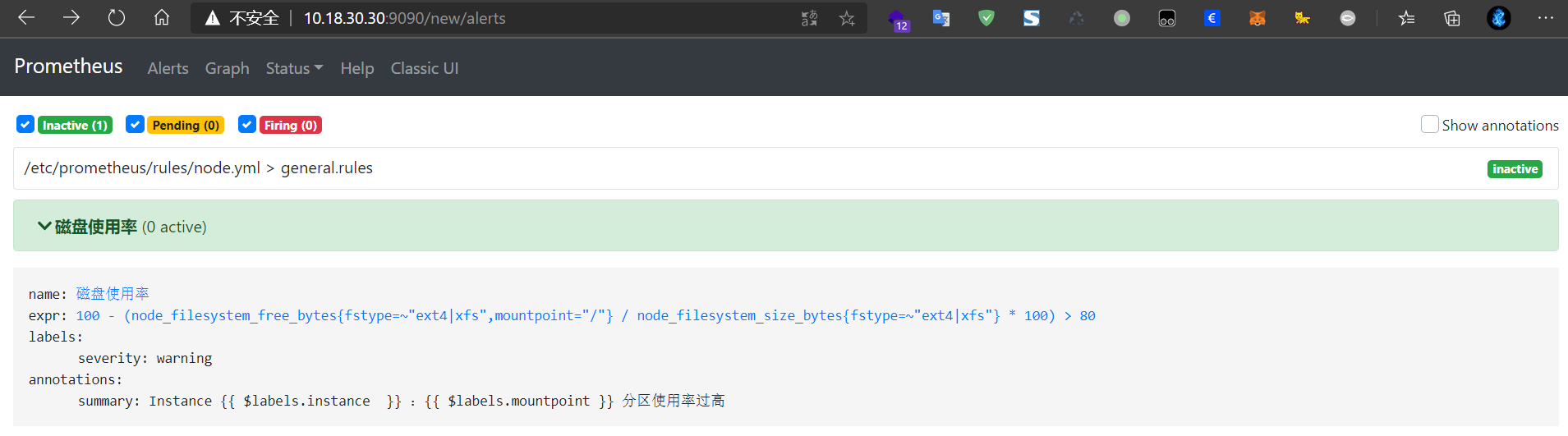
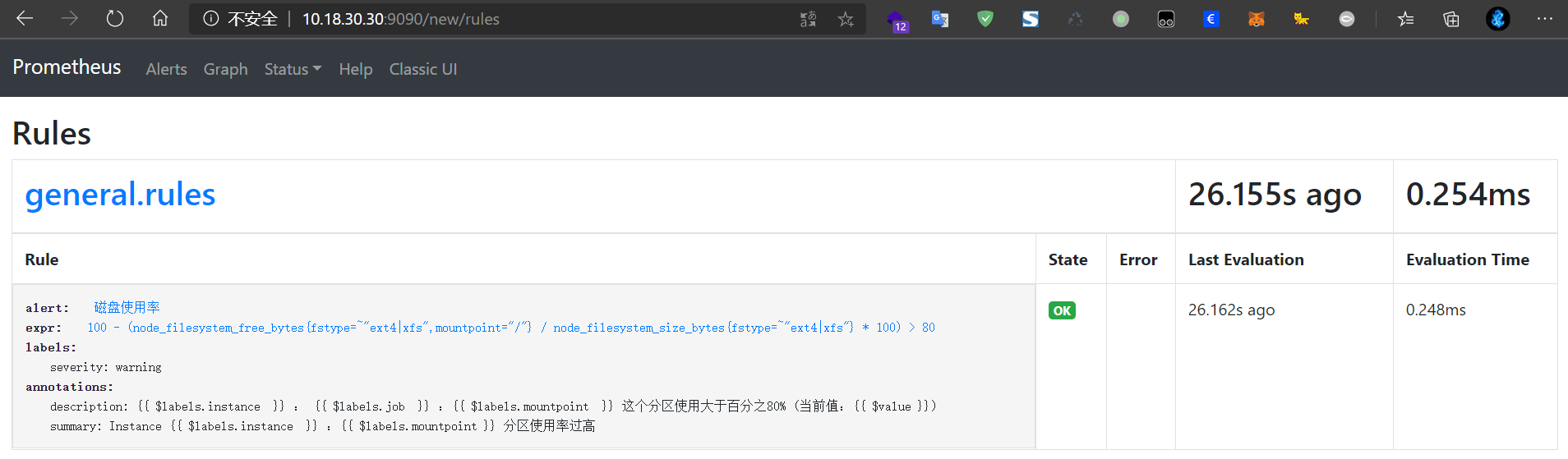
Prometheus + Alertmanager 实现告警
在上面,举例了 Prometheus 怎么配置告警的规则,接下来将配合 Alertmanager 实现按照规则去告警,并发送邮件
在 30 上操作
# 部署 Alertmanager
mkdir -p /data/alertmanager && cd /data/alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
tar -xvf alertmanager-0.21.0.linux-amd64.tar.gz && mv alertmanager-0.21.0.linux-amd64/* . && vim alertmanager.yml
# 编写 Alertmanager 配置文件
vim alertmanager.yml
# 全局设置
global:
# 解析超时时间
resolve_timeout: 5m
# 使用 email 打开服务配置,根据实际填写
smtp_smarthost: 'smtp.exmail.qq.com:465'
# 指定通知报警的邮箱,根据实际填写
smtp_from: 'XXXX@XXXX'
# 邮箱用户名,根据实际填写
smtp_auth_username: 'XXXX@XXXX'
# 授权密码,根据实际填写
smtp_auth_password: 'XXXX'
# 是否启用 tls
smtp_require_tls: false
# 告警如何发送分配
route:
# 采用哪个标签作为分组的依据
group_by: ['alertname']
# 分组等待的时间
group_wait: 10s
# 上下两组发送告警的间隔时间
group_interval: 10s
# 重复发送告警时间。默认 1h
repeat_interval: 1m
# 定义谁来通知报警
receiver: 'mail'
# 告警接收者
receivers:
# 报警来源自定义名称
- name: 'mail'
# 通过邮箱发送报警
email_configs:
# 指定接收端 email,根据实际填写
- to: 'XXXX@XXXX'
# 修改 Prometheus 配置文件,引入告警插件
vim /data/prometheus/prometheus.yml
# 添加以下这段
alerting:
alertmanagers:
- static_configs:
# Alertmanager 部署的地址和监听的端口
- targets: ["10.18.30.30:9093"]
# 设置开机自动启动 Alertmanager
chmod 755 /etc/rc.d/rc.local && cat >> /etc/rc.d/rc.local <<EOF
nohup /data/alertmanager/alertmanager --config.file="/data/alertmanager/alertmanager.yml" > /data/alertmanager/alertmanager.log 2>&1 &
EOF
# 启动 Alertmanager
nohup /data/alertmanager/alertmanager --config.file="/data/alertmanager/alertmanager.yml" > /data/alertmanager/alertmanager.log 2>&1 &
# 重启 Prometheus
docker restart cf_prometheus
访问对应地址能看到 Alertmanager 获取到的告警以及动作,这里因为没告警,所以还是空白的
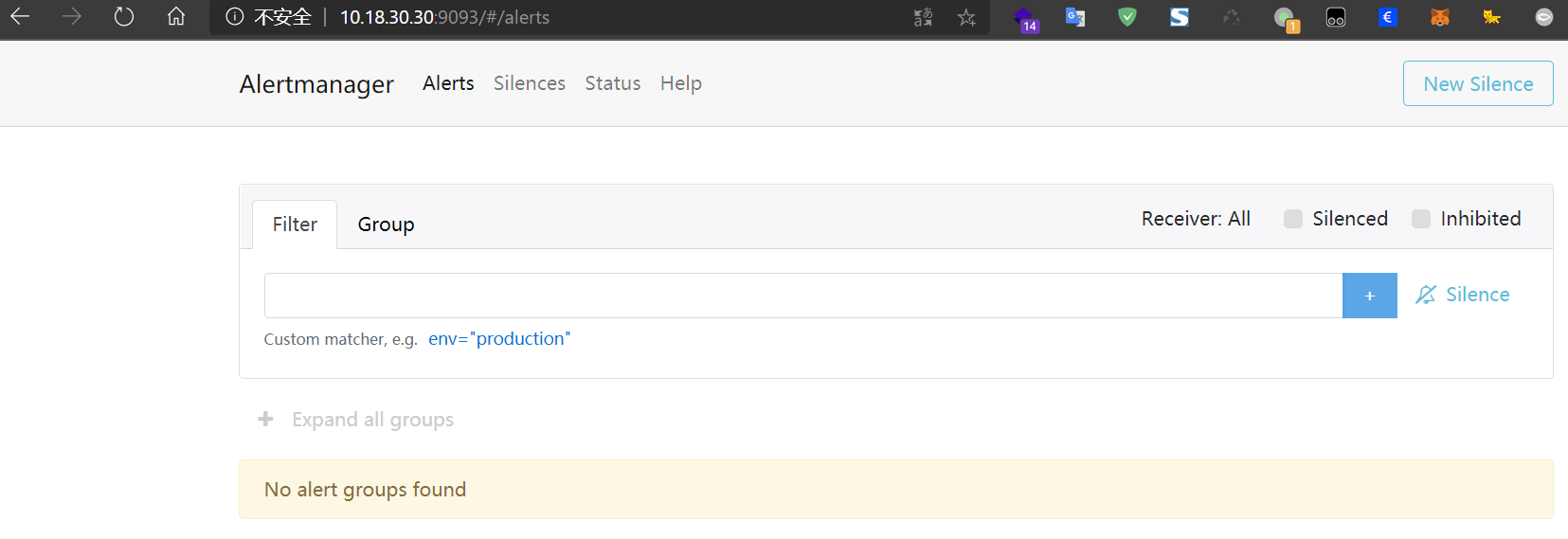
人造告警,测试效果
修改 /data/prometheus/rules/node.yml 对应内容
# 修改报警条件,这里改为大于 5% 的时候就报警
vim /data/prometheus/rules/node.yml
expr: 100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 5
description: "{{ $labels.instance }} : {{ $labels.job }} :{{ $labels.mountpoint }} 这个分区使用大于百分之 5% (当前值:{{ $value }})"
# 把配置文件复制到容器
docker cp /data/prometheus/rules cf_prometheus:/etc/prometheus/
# 重启 prometheus
docker restart cf_prometheus
静待 1 分钟,到 Prometheus 上查看是否有告警的信息
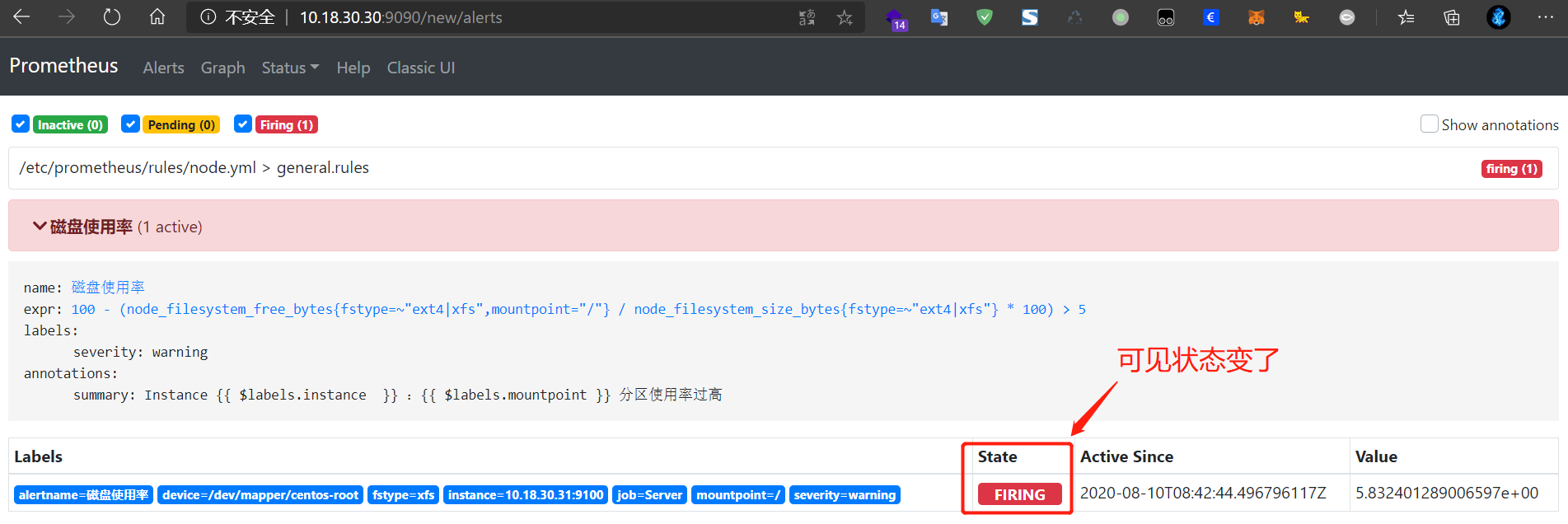
到 Alertmanager 页面上查看是否有告警信息和是否触发了动作
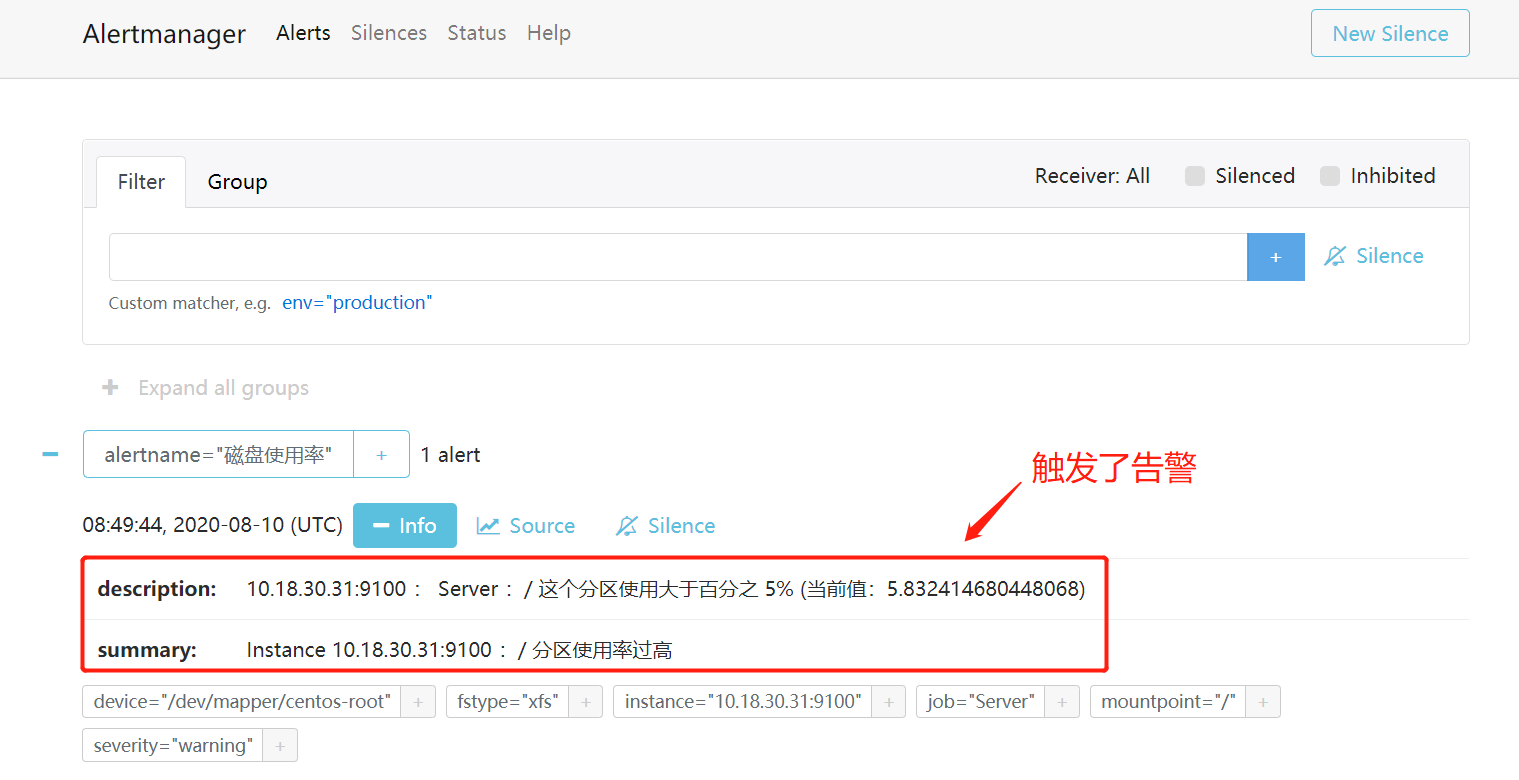
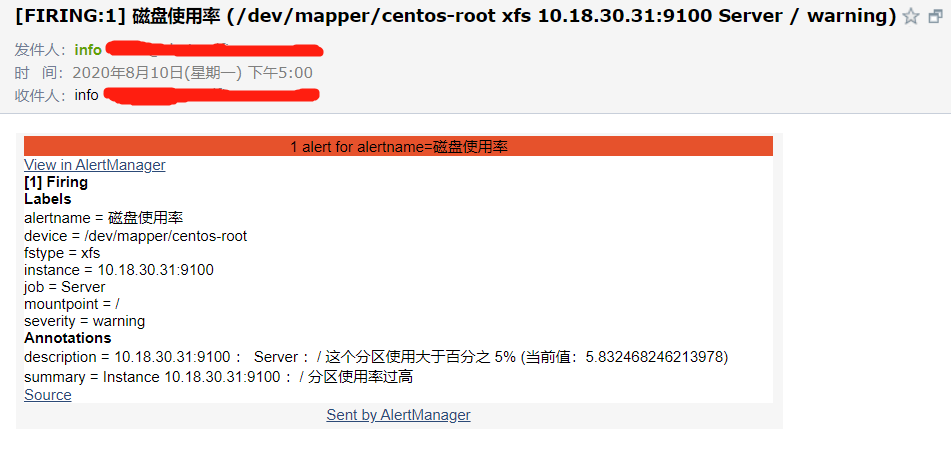
最终也能收到告警邮件
版权声明:
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
Linux 小白鼠!
觉得文章不错,打赏一点吧,1分也是爱~
打赏
 微信
微信
支付宝